卷积神经网络CNN
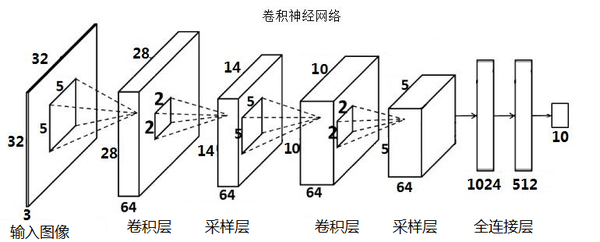
1. 卷积神经网络 (CNN) 用于图像分类
任务假设: 我们有一个图像数据集,每张图片对应一个类别(例如,CIFAR-10 数据集中的10个类别:飞机、汽车、鸟、猫等)。 模型输入是一张图片,输出是该图片属于各个类别的概率。
模型结构设想 (类似 VGGNet 的简化版思路):
- 多个卷积块 (Convolutional Blocks): 每个卷积块包含:
- 一个或多个
Conv2d层,用于提取特征。 - 一个
ReLU激活函数,引入非线性。 - 一个
MaxPool2d层,用于降采样,减少特征图尺寸,增大感受野。 - (可选)
BatchNorm2d层,用于稳定训练,加速收敛。
- 一个或多个
- 展平层 (Flatten Layer): 将最后一个卷积块输出的多维特征图展平成一维向量。
- 全连接层 (Fully Connected Layers):
- 一个或多个
Linear层,用于对展平后的特征进行分类。 ReLU激活函数。Dropout层,防止过拟合。
- 一个或多个
- 输出层 (Output Layer): 最后一个
Linear层,输出类别数量的 logits。
代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class ComplexCNN(nn.Module):
def __init__(self, num_classes=10):
"""
初始化CNN模型层。
参数:
num_classes (int): 输出类别的数量。
"""
super().__init__()
# --- 卷积块 1 ---
# 输入: (batch_size, 3, 32, 32) - 假设输入是 32x32 的 RGB 图像
self.conv_block1 = nn.Sequential(
# 第一个卷积层:3个输入通道(RGB),输出32个特征图,卷积核大小3x3,填充1(保持尺寸)
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, padding=1),
nn.BatchNorm2d(32), # 归一化,加速收敛,稳定训练
nn.ReLU(), # 激活函数
# 第二个卷积层:输入32,输出32,卷积核3x3,填充1
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2) # 最大池化,尺寸减半 (32x32 -> 16x16)
# 输出: (batch_size, 32, 16, 16)
)
# --- 卷积块 2 ---
self.conv_block2 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2) # 尺寸减半 (16x16 -> 8x8)
# 输出: (batch_size, 64, 8, 8)
)
# --- 卷积块 3 ---
self.conv_block3 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2) # 尺寸减半 (8x8 -> 4x4)
# 输出: (batch_size, 128, 4, 4)
)
# --- 全连接层 ---
# 展平后的特征数量需要计算: 128 (通道数) * 4 (高度) * 4 (宽度)
self.flattened_features_dim = 128 * 4 * 4
self.fc_layers = nn.Sequential(
nn.Flatten(), # 将多维特征图展平成一维向量
nn.Linear(self.flattened_features_dim, 512),
nn.ReLU(),
nn.Dropout(0.5), # Dropout 防止过拟合
nn.Linear(512, num_classes) # 输出层,输出类别 logits
)
def forward(self, x):
"""
定义模型的前向传播。
参数:
x (Tensor): 输入图像张量,形状 (batch_size, channels, height, width)。
返回:
logits (Tensor): 形状 (batch_size, num_classes) 的类别分数。
"""
# print(f"Input shape: {x.shape}")
x = self.conv_block1(x)
# print(f"After conv_block1: {x.shape}")
x = self.conv_block2(x)
# print(f"After conv_block2: {x.shape}")
x = self.conv_block3(x)
# print(f"After conv_block3: {x.shape}")
logits = self.fc_layers(x)
# print(f"Logits shape: {logits.shape}")
return logits
# --- 模拟参数和输入 ---
NUM_CLASSES_CNN = 10 # 例如 CIFAR-10 有10个类别
BATCH_SIZE_CNN = 4
INPUT_CHANNELS_CNN = 3
IMAGE_HEIGHT_CNN = 32
IMAGE_WIDTH_CNN = 32
# 实例化模型
cnn_model = ComplexCNN(num_classes=NUM_CLASSES_CNN)
print("CNN 模型结构:\n", cnn_model)
total_params_cnn = sum(p.numel() for p in cnn_model.parameters() if p.requires_grad)
print(f"\nCNN 模型总可训练参数数量: {total_params_cnn:,}")
# --- 模拟输入数据 ---
dummy_images = torch.randn(BATCH_SIZE_CNN, INPUT_CHANNELS_CNN, IMAGE_HEIGHT_CNN, IMAGE_WIDTH_CNN)
print(f"\n模拟输入图像形状: {dummy_images.shape}")
# --- 模型前向传播 ---
cnn_model.eval() # 设置为评估模式
with torch.no_grad():
cnn_logits = cnn_model(dummy_images)
print("\nCNN 模型输出 Logits (形状: batch_size, num_classes):")
print(cnn_logits)
print("CNN Logits 形状:", cnn_logits.shape)
CNN 通俗解释:
-
__init__(初始化 / "蓝图设计"):conv_block1,conv_block2,conv_block3: 这三个是“特征提取器”模块。每个模块都像一套“滤镜”。nn.Conv2d: 真正的“滤镜”。它会在输入图片上滑动,寻找特定的图案(边缘、角点、纹理等)。in_channels是输入有多少层颜色/特征,out_channels是我们想提取多少种新特征,kernel_size是滤镜的大小,padding是在图片边缘补一圈像素,防止滤镜滑出去后图片变太小。nn.BatchNorm2d: 像一个“调节器”,在每层卷积后调整数据的分布,让训练更稳定、更快。nn.ReLU: 激活函数,像一个“开关”,只让正数的信号通过,增加模型的非线性能力,让它能学更复杂的东西。nn.MaxPool2d: “浓缩器”。它会把一个小区域里的最大值挑出来,丢掉其他信息。这样做可以减少数据量,让模型关注更显著的特征,并对物体位置的一些小变化不那么敏感。
fc_layers(全连接层): 这是“决策者”模块。nn.Flatten(): 在卷积层提取完特征后,得到的是一堆二维的特征图。这个层把它们“拍扁”成一个长长的一维向量。nn.Linear: 全连接层。它接收拍扁后的特征向量,通过学习权重,将这些特征组合起来,最终判断图片属于哪个类别。第一个Linear层通常将特征维度降低到一个较小的数目(例如512)。nn.Dropout: 在全连接层之间随机“关闭”一些神经元,防止模型太依赖某些特定特征组合(防止过拟合)。- 最后一个
nn.Linear: 输出最终的类别分数(logits),每个分数对应一个类别。
-
forward(前向传播 / "实际工作流程"):- 图片数据
x先后通过conv_block1,conv_block2,conv_block3。每通过一个卷积块,图片中的特征会被提取和浓缩,特征图的“深度”(通道数)可能会增加,但“高度”和“宽度”会因为池化而减小。 - 经过所有卷积块后,得到的特征图被
fc_layers中的Flatten层拍扁。 - 然后这个一维向量通过全连接层进行最终的分类决策,得到
logits。
- 图片数据
No comments to display
No comments to display