基于LSTM的文本分类任务
重点
正确的理解应该是(针对标准 Seq2Seq,不考虑有特殊输出层的编码器):
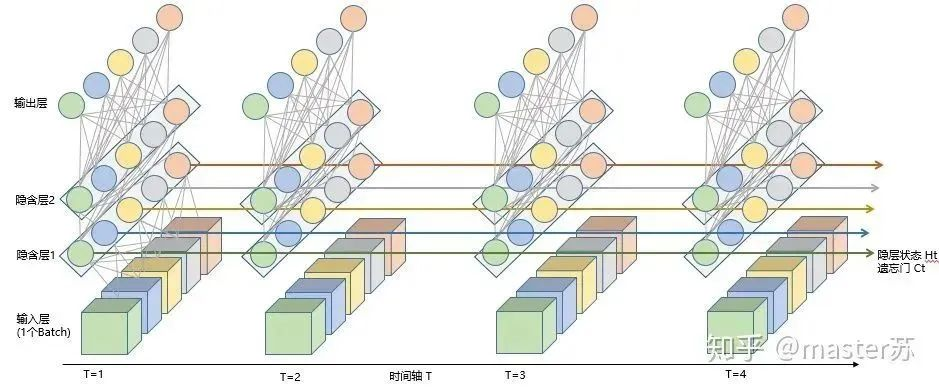
h_1和c_1的传递: 正如我们之前讨论的,在编码器的每个隐含层,h_t和c_t会一直向后传递到下一个时间步t+1,h_t即隐含层的输出,并不是输出层的输出y_t,隐含层的输出h_t不会丢弃,会被保存起来。- 编码器的最终“思想总结”: 当编码器处理完整个输入序列后 (到达最后一个时间步
T),编码器最后一个隐含层(例如图中的“隐含层2”)所输出的隐藏状态h_T^{(last\_layer)}和细胞状态c_T^{(last\_layer)}被认为是整个输入序列的压缩表示,即上下文向量 (Context Vector)。 - 上下文向量作为解码器的初始状态:
- 这个上下文向量 (通常是
h_T^{(last\_layer)}和c_T^{(last\_layer)}) 会被用作解码器第一个隐含层的初始隐藏状态和初始细胞状态。 - 也就是说,解码器开始生成输出序列时,它的“记忆”是被编码器对输入序列的“理解”所初始化的。
- 这个上下文向量 (通常是
所以,修正你的理解:
“对于编码器来说,h_t 和 c_t 在每个隐含层会一直向后传递。当编码器处理到输入序列的最后一个时刻 T 时,其最后一个隐含层所输出的隐藏状态 h_T 和细胞状态 c_T (这组状态通常被称为上下文向量),会被用作解码器的初始隐藏状态和初始细胞状态。”
想象一下你在读一篇很长的小说,或者听一个人讲一个复杂的故事。
-
普通人 (简单 RNN 的问题):
- 你可能会记住故事刚开始的情节,但随着故事越来越长,你很容易忘记几百页之前提到的某个重要线索或人物。你的“短期记忆”是有限的。
- 这就是简单循环神经网络 (RNN) 的问题:它们在处理长序列时,容易出现梯度消失或梯度爆炸,导致很难捕捉到序列中相隔很远的依赖关系(即“长期依赖”)。
-
记忆超群的人 (LSTM 的能力):
- 现在想象一个记忆力超群的人。他不仅能记住当前听到的内容,还能有选择地记住很久以前的关键信息,并且在需要的时候把这些信息调出来用。他还能判断哪些信息现在不重要了,可以暂时忘掉,以免大脑混乱。
- LSTM (Long Short-Term Memory,长短期记忆网络) 就扮演了这个“记忆超群的人”的角色。 它是一种特殊的循环神经网络,专门设计用来解决简单 RNN 的长期依赖问题。
LSTM 的核心秘诀:“门控机制” (Gating Mechanism)
LSTM 之所以能“记忆超群”,是因为它内部设计了几个巧妙的“门”(Gates)。这些门就像信息流的控制开关,决定了哪些信息应该被保留、哪些应该被遗忘、哪些应该被输出。
把 LSTM 的一个单元想象成一个有“记忆细胞 (Cell State)”的房间,这个细胞负责存储长期记忆。然后有三个主要的“门卫”来管理进出这个房间和对外输出的信息:
-
遗忘门 (Forget Gate):
- 作用: 决定从“记忆细胞”中丢弃哪些旧信息。
- 例子: 当你读到一个新的章节,涉及到新的主角时,遗忘门可能会决定“前一个章节的配角信息现在不那么重要了,可以适当忘记一些”,以便为新信息腾出空间。
- 它会查看当前的输入和前一个时刻的短期记忆,然后输出一个介于0和1之间的值,告诉记忆细胞的每个部分应该保留多少(1代表完全保留,0代表完全忘记)。
-
输入门 (Input Gate):
- 作用: 决定哪些新的信息要被存储到“记忆细胞”中。
- 例子: 当你读到一个新的关键线索时,输入门会判断“这个线索很重要,需要记下来”。
- 它包含两部分:
- 一部分决定哪些值需要更新(类似于遗忘门,输出0-1的值)。
- 另一部分创建一个候选值向量,准备加入到细胞状态中。
- 两者结合,决定了记忆细胞中哪些部分需要更新,以及用什么新值来更新。
-
输出门 (Output Gate):
- 作用: 决定从“记忆细胞”中提取哪些信息作为当前时刻的输出(也作为下一个时刻的短期记忆)。
- 例子: 当你需要根据已知信息做一个判断或回答一个问题时,输出门会从你的长期记忆中挑选相关的部分,并结合当前情况形成答案。
- 它会根据当前的输入、前一个时刻的短期记忆和当前的细胞状态,决定细胞状态的哪些部分可以输出。
简单来说,LSTM 就是通过这三个门,智能地控制信息在“记忆细胞”中的流入、流出和保留,从而能够有效地捕捉和利用序列中的长期依赖关系。
现在我们来看你提供的 PyTorch 代码中的 nn.LSTM 参数:
self.lstm = nn.LSTM(embedding_dim, # input_size
hidden_dim, # hidden_size
num_layers=n_layers, # num_layers
bidirectional=bidirectional, # bidirectional
dropout=dropout_prob if n_layers > 1 else 0, # dropout
batch_first=True) # batch_first
-
embedding_dim(对应input_size):- 作用: 告诉 LSTM 层,在序列的每一个时间步,输入进来的“词”或“符号”是用多少维的向量来表示的。
- 例子: 如果你把单词“猫”转换成了一个 100 维的向量(词嵌入),那么
embedding_dim就是 100。LSTM 在每个时间点都会接收一个这样维度的向量。
-
hidden_dim(对应hidden_size):- 可以理解为LSTM层中LSTM神经元的个数
- 作用: 定义 LSTM 内部“短期记忆”(隐藏状态,Hidden State)和“长期记忆”(细胞状态,Cell State)的维度大小。这个维度也决定了 LSTM 在每个时间步输出的特征向量的维度(如果是单向 LSTM 的话)。
- 例子: 如果
hidden_dim是 256,那么 LSTM 在每个时间步的“思考结果”(隐藏状态)就是一个 256 维的向量。这个“思考结果”会传递给下一个时间步,也会作为当前时间步的输出。 - 重要性:
hidden_dim的大小影响了模型的“记忆容量”和“表达能力”。太小可能记不住足够的信息,太大则可能导致参数过多,容易过拟合,计算也更慢。
-
num_layers=n_layers:- 可以理解为LSTM层个数
- 作用: 指定要堆叠多少层 LSTM。就像搭积木一样,你可以把多个 LSTM 层叠在一起。
- 例子: 如果
num_layers=2,意味着序列数据会先经过第一个 LSTM 层处理,第一个 LSTM 层的输出(每个时间步的隐藏状态)会作为第二个 LSTM 层的输入,再进行处理。 - 好处: 更深的 LSTM (多层) 可以学习到更复杂、更抽象的序列模式。第一层可能学习一些局部的、底层的模式,更高层则在这些模式的基础上学习更全局、更高级的模式。
- 注意: 层数越多,参数也越多,训练也越困难。
-
bidirectional=bidirectional(通常是一个布尔值True或False):- 作用: 决定是否使用双向 LSTM (BiLSTM)。
- 单向 LSTM (
bidirectional=False): 像我们正常阅读一样,从序列的开头按顺序处理到结尾(从左到右)。它在某个时间点的输出只依赖于之前的信息。 - 双向 LSTM (
bidirectional=True): 它包含两个独立的 LSTM:一个从前向后处理序列,另一个从后向前处理序列。然后,在每个时间点,这两个 LSTM 的隐藏状态会被拼接 (concatenate) 起来(或者用其他方式如相加、平均等结合)作为最终的输出。 - 例子: 理解一句话“我今天不开心”。
- 单向 LSTM 读到“不”的时候,可能还不知道后面的“开心”是什么。
- 双向 LSTM 的前向部分处理到“不”,后向部分则已经处理了“开心”。结合起来,模型能更好地理解“不”在这里的否定意义。
- 好处: 双向 LSTM 能够同时利用过去和未来的上下文信息,对于很多 NLP 任务(如情感分析、命名实体识别)通常能带来更好的性能。
- 注意: 如果是双向的,那么在每个时间步输出的隐藏状态维度会是
hidden_dim * 2(因为是两个方向的隐藏状态拼接)。
-
dropout=dropout_prob if n_layers > 1 else 0:- 作用: 在多层 LSTM 中,在除了最后一层之外的每一层 LSTM 的输出上应用 Dropout 正则化。Dropout 会在训练时随机地将一些神经元的输出置为零,以防止过拟合。
- 例子: 如果
num_layers=3且dropout_prob=0.5,那么第一层 LSTM 的输出在进入第二层 LSTM 之前,会经过一个 Dropout 层(丢弃概率为0.5);第二层 LSTM 的输出在进入第三层 LSTM 之前,也会经过一个 Dropout 层。最后一层(第三层)的输出则不加 Dropout。 - 条件
if n_layers > 1 else 0的含义: 这段代码的意思是,只有当 LSTM 的层数大于 1 时,才应用dropout_prob指定的 dropout 率;如果只有一层 LSTM,则不应用 dropout(dropout 率为0)。这是因为 dropout 通常用于层与层之间,单层 LSTM 内部没有“中间层输出”可以应用 dropout。 - 好处: 增强模型的泛化能力,减少对训练数据的过拟合。
-
batch_first=True:- 作用: 这是一个非常重要的参数,它定义了输入和输出张量的维度顺序。
batch_first=True(常用): 输入张量的形状是(batch_size, seq_len, input_size),输出张量的形状是(batch_size, seq_len, hidden_size * num_directions)。也就是说,批次大小是第一个维度。batch_first=False(默认值): 输入张量的形状是(seq_len, batch_size, input_size),输出张量的形状是(seq_len, batch_size, hidden_size * num_directions)。也就是说,序列长度是第一个维度。- 为什么重要: 你在准备输入数据时,需要确保数据的维度顺序与这里设置的一致。大多数情况下,我们习惯于将
batch_size放在第一个维度,所以batch_first=True是一个方便的选择。
总结一下 LSTM 的工作流程(结合参数):
- 输入: 一批序列数据,每个序列由多个时间步组成,每个时间步是一个
embedding_dim维的向量。由于batch_first=True,输入形状是(batch_size, seq_len, embedding_dim)。 - 处理:
- 数据流经
n_layers个堆叠的 LSTM 层。 - 每个 LSTM 单元内部通过遗忘门、输入门、输出门来更新其细胞状态(长期记忆)和隐藏状态(短期记忆)。
hidden_dim定义了这些状态的维度。 - 如果
bidirectional=True,则每个堆叠层都有一个前向 LSTM 和一个后向 LSTM 并行工作,它们的隐藏状态会拼接。 - 如果在多层 LSTM 中且
dropout_prob > 0,则在非最后一层的 LSTM 输出上会应用 dropout。
- 数据流经
- 输出:
output张量: 包含最后一层 LSTM 在每个时间步的隐藏状态。形状是(batch_size, seq_len, hidden_dim * num_directions)(其中num_directions是 1(单向)或 2(双向))。这个输出通常用于需要序列中每个位置信息的任务(如序列标注)。(h_n, c_n)元组 (隐藏状态和细胞状态):h_n: 包含序列中最后一个时间步的所有堆叠层的隐藏状态。形状是(num_layers * num_directions, batch_size, hidden_dim)。c_n: 包含序列中最后一个时间步的所有堆叠层的细胞状态。形状是(num_layers * num_directions, batch_size, hidden_dim)。h_n(或者h_n的一部分) 经常被用作整个序列的编码表示,用于后续的分类、回归等任务。
全流程概览
- 数据准备与预处理:
- 定义示例数据(文本和标签)。
- 构建词汇表 (Vocabulary):将词语映射到整数 ID,反之亦然。
- 文本分词 (Tokenization) 并转换为 ID 序列。
- 序列填充 (Padding):使同一批次内的所有序列长度一致。
- 创建
Dataset: 定义如何根据索引获取单个处理好的样本(ID序列和标签)。 - 创建
DataLoader: 批量加载数据,并使用自定义的collate_fn来处理批次内的填充。 - 模型定义 (
TextClassifierLSTM): (使用我们之前的定义) - 训练准备: 实例化模型、损失函数、优化器。
- 训练循环: 包含前向传播、损失计算、反向传播、参数更新。
- 评估函数: 计算在验证集或测试集上的损失和准确率。
- 主执行流程: 将以上步骤串联起来。
代码实现:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader, TensorDataset
import numpy as np
import random
# --- 0. 设置参数和设备 ---
# 数据参数
VOCAB_SIZE = 5000 # 假设我们的词典里有 5000 个不同的词 (包括特殊的填充符和未知词)
MAX_SEQ_LEN = 50 # 我们处理的每个句子(序列)都被填充或截断到了这个固定长度
PAD_IDX = 0 # 用数字 0 来代表填充符(比如句子不够长时,用0补齐)
# 模型参数
EMBEDDING_DIM = 100 # 每个词会被转换成一个 100 维的向量(词嵌入)
HIDDEN_DIM = 256 # LSTM 内部“思考”时用的向量维度,可以理解为记忆单元的大小
OUTPUT_DIM = 3 # 最终我们要把文本分成 3 个类别
N_LAYERS = 2 # 我们要堆叠 2 层 LSTM,像搭积木一样,让模型更强大
BIDIRECTIONAL = True # 使用双向 LSTM,模型会从前向后和从后向前分别读一遍句子,获取更全面的信息
DROPOUT_PROB = 0.5 # 在训练时,随机“丢弃”一些神经元输出的概率,防止模型死记硬背(过拟合)
# 训练参数
BATCH_SIZE = 32 # 每次训练模型时,喂给它 32 个句子
LEARNING_RATE = 0.001 # 模型学习调整参数时的“步子大小”
NUM_EPOCHS = 10 # 我们要把整个训练数据集完整地过 10 遍
CLIP_GRAD = 1.0 # 梯度裁剪的阈值,防止梯度过大导致训练不稳定
# 自动选择用 GPU 还是 CPU 来训练
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}") # 打印出当前使用的设备
# --- 1. 模拟预处理好的数据 ---
# 这个函数用来生成一些假的文本数据,模拟我们真实场景中预处理好的样子
def generate_mock_data(num_samples, vocab_size, max_seq_len, num_classes, pad_idx):
texts = [] # 存储所有句子的词ID序列
lengths = [] # 存储每个句子在填充前的真实长度
labels = [] # 存储每个句子的类别标签
for _ in range(num_samples):
# 随机生成一个句子的真实长度 (在最大长度的一半到最大长度之间)
seq_len = random.randint(max_seq_len // 2, max_seq_len)
lengths.append(seq_len)
# 生成一个随机的词ID序列 (词ID从1开始,因为0是填充符)
sequence = np.random.randint(1, vocab_size, size=seq_len)
# 如果句子长度不够 max_seq_len,用 pad_idx (0) 来填充
padded_sequence = np.pad(sequence, (0, max_seq_len - seq_len), 'constant', constant_values=pad_idx)
texts.append(padded_sequence)
# 随机给这个句子分配一个类别标签
labels.append(random.randint(0, num_classes - 1))
# 把Python列表转换成PyTorch张量
return (torch.tensor(np.array(texts), dtype=torch.long), # 文本数据,形状 (样本数, 最大序列长度)
torch.tensor(np.array(labels), dtype=torch.long), # 标签数据,形状 (样本数,)
torch.tensor(np.array(lengths), dtype=torch.long)) # 长度数据,形状 (样本数,)
num_train_samples = 2000 # 生成 2000 条训练数据
num_val_samples = 500 # 生成 500 条验证数据
# 生成训练数据
train_texts_tensor, train_labels_tensor, train_lengths_tensor = generate_mock_data(
num_train_samples, VOCAB_SIZE, MAX_SEQ_LEN, OUTPUT_DIM, PAD_IDX
)
# 生成验证数据
val_texts_tensor, val_labels_tensor, val_lengths_tensor = generate_mock_data(
num_val_samples, VOCAB_SIZE, MAX_SEQ_LEN, OUTPUT_DIM, PAD_IDX
)
print(f"Train texts shape: {train_texts_tensor.shape}") # 应该输出 (2000, 50)
print(f"Train labels shape: {train_labels_tensor.shape}") # 应该输出 (2000,)
print(f"Train lengths shape: {train_lengths_tensor.shape}")# 应该输出 (2000,)
# --- 2. 创建 Dataset 和 DataLoader ---
# TensorDataset 可以方便地把我们的张量数据打包成一个数据集对象
train_dataset = TensorDataset(train_texts_tensor, train_labels_tensor, train_lengths_tensor)
val_dataset = TensorDataset(val_texts_tensor, val_labels_tensor, val_lengths_tensor)
# DataLoader 帮我们把数据集分成小批次 (batch),并且可以打乱数据顺序
# 使用默认的 collate_fn,因为它能很好地处理已经是张量的输入
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True) # 训练时打乱顺序
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False) # 验证时不打乱
# --- 3. 模型定义 (TextClassifierLSTM) ---
class TextClassifierLSTM(nn.Module): # 定义我们自己的LSTM文本分类模型,它继承自PyTorch的 nn.Module
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers,
bidirectional, dropout_prob, pad_idx):
super().__init__() # 调用父类的初始化方法
# 1. 词嵌入层 (Embedding Layer)
# 把每个词的ID (一个数字) 转换成一个稠密的向量 (词嵌入)
# padding_idx=pad_idx 告诉嵌入层,遇到填充符时,它的嵌入向量应该是零,并且不参与梯度更新
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)
# 2. LSTM 层 (Recurrent Layer)
# LSTM 能够处理序列数据,并捕捉序列中的长期依赖关系。
# input_size: 每个时间步输入特征的维度,这里是词嵌入的维度 embedding_dim。
# hidden_size: LSTM 隐藏状态和细胞状态的维度。
# num_layers: 堆叠的 LSTM 层数。更深的 LSTM 可以学习更复杂的模式。
# bidirectional: 如果为 True,则创建一个双向 LSTM。双向 LSTM 会从前向后和从后向前处理序列,
# 然后拼接两个方向的隐藏状态,能更好地捕捉上下文。
# dropout: 在多层 LSTM 中,在除最后一层外的每层 LSTM 的输出上应用 dropout。
# batch_first=True: 表示输入和输出张量的第一个维度是 batch_size。
self.lstm = nn.LSTM(embedding_dim,
hidden_dim,
num_layers=n_layers,
bidirectional=bidirectional,
dropout=dropout_prob if n_layers > 1 else 0, # 只有多层LSTM才在中间加dropout
batch_first=True)
# 3. Dropout 层 (Regularization Layer)
# 在全连接层之前也加一个 Dropout,进一步防止过拟合
self.dropout = nn.Dropout(dropout_prob)
# 4. 全连接层 (Fully Connected Layer / Linear Layer)
# 把 LSTM 的最终输出转换成我们想要的类别数量 (output_dim)
# 如果 LSTM 是双向的,那么它的输出维度是 hidden_dim * 2,所以全连接层的输入维度也要相应调整
fc_input_dim = hidden_dim * 2 if bidirectional else hidden_dim
self.fc = nn.Linear(fc_input_dim, output_dim)
def forward(self, text_ids, text_lengths): # 定义数据在模型中如何流动 (前向传播)
# text_ids: (batch_size, seq_len) -> 一批句子的词ID
# text_lengths: (batch_size) -> 这批句子中每个句子的真实长度 (没有填充的部分)
# 1. 词嵌入
# (batch_size, seq_len) -> (batch_size, seq_len, embedding_dim)
embedded = self.embedding(text_ids)
# 对嵌入向量应用 dropout
embedded = self.dropout(embedded)
# 2. 打包序列 (Packing sequences) - 优化技巧
# LSTM 在处理变长序列时,如果直接输入填充后的序列,会对填充部分也进行不必要的计算。
# pack_padded_sequence 可以告诉 LSTM 每个序列的真实长度,让它只对有效部分进行计算,提高效率。
# text_lengths 需要是 CPU 上的 LongTensor
packed_embedded = nn.utils.rnn.pack_padded_sequence(
embedded, text_lengths.cpu().long(), batch_first=True, enforce_sorted=False # enforce_sorted=False 表示输入序列不需要按长度排序
)
# 3. LSTM 处理
# packed_output 是 LSTM 在每个时间步的输出 (打包格式)
# hidden 是最后一个时间步的隐藏状态,cell 是最后一个时间步的细胞状态
packed_output, (hidden, cell) = self.lstm(packed_embedded)
# (我们这里不需要 packed_output,通常用 hidden 来做分类)
# 我们可以选择解包 packed_output,如果需要每个时间步的输出:
# output, output_lengths = nn.utils.rnn.pad_packed_sequence(packed_output, batch_first=True)
# 4. 提取并处理最终的隐藏状态
# hidden 的形状是 (n_layers * num_directions, batch_size, hidden_dim)
# 我们通常取最后一层 LSTM 的最终隐藏状态作为句子的表示
if self.lstm.bidirectional:
# 如果是双向 LSTM,hidden 张量的前 n_layers 个是前向的,后 n_layers 个是后向的。
# hidden[-2,:,:] 是最后一层前向 LSTM 的最终隐藏状态。
# hidden[-1,:,:] 是最后一层后向 LSTM 的最终隐藏状态。
# 我们把它们拼接起来。
# (batch_size, hidden_dim * 2)
hidden_concat = torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1)
else:
# 如果是单向 LSTM,直接取最后一层的最终隐藏状态。
# (batch_size, hidden_dim)
hidden_concat = hidden[-1,:,:]
# 对提取出的隐藏状态再应用 Dropout
dropped_hidden = self.dropout(hidden_concat)
# 5. 全连接层进行分类
# (batch_size, output_dim)
logits = self.fc(dropped_hidden) # logits 是模型对每个类别的原始打分
return logits
# --- 4. 训练准备 ---
# 创建模型实例,并把它放到选择的设备上 (CPU 或 GPU)
model_lstm = TextClassifierLSTM(VOCAB_SIZE, EMBEDDING_DIM, HIDDEN_DIM, OUTPUT_DIM,
N_LAYERS, BIDIRECTIONAL, DROPOUT_PROB, PAD_IDX).to(device)
# 定义损失函数:交叉熵损失,常用于多分类问题
# 它会比较模型的原始打分 (logits) 和真实的类别标签
criterion_lstm = nn.CrossEntropyLoss()
# 定义优化器:Adam 优化器,一种常用的梯度下降算法的变种,用来更新模型的参数
optimizer_lstm = optim.Adam(model_lstm.parameters(), lr=LEARNING_RATE)
# 计算模型中可以训练的参数总数量
total_params_lstm = sum(p.numel() for p in model_lstm.parameters() if p.requires_grad)
print(f"\nLSTM 模型总可训练参数数量: {total_params_lstm:,}") # 打印参数数量,方便了解模型大小
# --- 5. 训练循环 ---
print("\n--- Starting LSTM Text Classifier Training (Simplified Data Preprocessing) ---")
for epoch in range(NUM_EPOCHS): # 外层循环,控制训练多少个 epoch
model_lstm.train() # 把模型设置为训练模式 (这会启用 Dropout 等只在训练时使用的层)
epoch_train_loss = 0 # 当前 epoch 的总训练损失
epoch_train_correct = 0 # 当前 epoch 训练时预测正确的样本数
epoch_train_total = 0 # 当前 epoch 训练的总样本数
# 内层循环,遍历训练数据加载器中的每个批次
for batch_idx, (texts_batch, labels_batch, lengths_batch) in enumerate(train_loader):
# 把数据也放到选择的设备上
texts_batch = texts_batch.to(device)
labels_batch = labels_batch.to(device)
# lengths_batch 会在模型的 forward 方法中被移到 CPU (因为 pack_padded_sequence 要求)
optimizer_lstm.zero_grad() # 清空上一批次的梯度,防止梯度累积
# 前向传播:把数据喂给模型,得到预测结果 (logits)
predictions_logits = model_lstm(texts_batch, lengths_batch)
# 计算损失:比较预测结果和真实标签
loss = criterion_lstm(predictions_logits, labels_batch)
# 反向传播:根据损失计算梯度
loss.backward()
# 梯度裁剪:防止梯度爆炸,使得训练更稳定
torch.nn.utils.clip_grad_norm_(model_lstm.parameters(), CLIP_GRAD)
# 更新参数:优化器根据梯度调整模型的权重
optimizer_lstm.step()
# 累积当前批次的损失和准确率信息
epoch_train_loss += loss.item() * texts_batch.size(0) # loss.item() 是当前批次的平均损失,乘以批次大小得到批次总损失
_, predicted_labels = torch.max(predictions_logits, 1) # 从 logits 中选出概率最大的那个类别作为预测类别
epoch_train_correct += (predicted_labels == labels_batch).sum().item() # 计算预测正确的数量
epoch_train_total += labels_batch.size(0) # 累积处理的样本总数
if (batch_idx + 1) % 20 == 0: # 每处理 20 个批次,打印一次信息
print(f'Epoch [{epoch+1}/{NUM_EPOCHS}], Step [{batch_idx+1}/{len(train_loader)}], Batch Loss: {loss.item():.4f}')
# 计算当前 epoch 的平均训练损失和平均训练准确率
avg_epoch_train_loss = epoch_train_loss / epoch_train_total
avg_epoch_train_acc = epoch_train_correct / epoch_train_total
print(f"End of Epoch [{epoch+1}/{NUM_EPOCHS}]")
print(f"\tTraining Loss: {avg_epoch_train_loss:.4f} | Training Acc: {avg_epoch_train_acc*100:.2f}%")
# --- 6. 评估模型 (在验证集上) ---
model_lstm.eval() # 把模型设置为评估模式 (这会关闭 Dropout 等只在训练时使用的层)
epoch_val_loss = 0 # 当前 epoch 的总验证损失
epoch_val_correct = 0 # 当前 epoch 验证时预测正确的样本数
epoch_val_total = 0 # 当前 epoch 验证的总样本数
with torch.no_grad(): # 在评估时,我们不需要计算梯度,可以节省计算资源
for texts_batch_val, labels_batch_val, lengths_batch_val in val_loader: # 遍历验证数据加载器
texts_batch_val = texts_batch_val.to(device)
labels_batch_val = labels_batch_val.to(device)
predictions_logits_val = model_lstm(texts_batch_val, lengths_batch_val) # 前向传播
loss_val = criterion_lstm(predictions_logits_val, labels_batch_val) # 计算损失
# 累积验证集的损失和准确率信息
epoch_val_loss += loss_val.item() * texts_batch_val.size(0)
_, predicted_labels_val = torch.max(predictions_logits_val, 1)
epoch_val_correct += (predicted_labels_val == labels_batch_val).sum().item()
epoch_val_total += labels_batch_val.size(0)
# 计算当前 epoch 的平均验证损失和平均验证准确率
avg_epoch_val_loss = epoch_val_loss / epoch_val_total
avg_epoch_val_acc = epoch_val_correct / epoch_val_total
print(f"\tValidation Loss: {avg_epoch_val_loss:.4f} | Validation Acc: {avg_epoch_val_acc*100:.2f}%")
print("-" * 60) # 打印分隔线
print("LSTM Text Classifier Training Finished.")
# --- (可选) 简单的预测函数 (假设有一个 vocab_obj 来数值化) ---
# 为了完整性,我们还是需要一个简单的方式来转换文本到ID序列
# 假设我们有一个预先构建好的 stoi 字典 (string to int)
mock_stoi = {f"word{i}": i+2 for i in range(VOCAB_SIZE - 2)} # word0, word1 ...
mock_stoi["<PAD>"] = PAD_IDX
mock_stoi["<UNK>"] = 1 # 假设 UNK_TOKEN 的 ID 是 1
def numericalize_simple(text, stoi_map, max_len, pad_idx, unk_idx):
tokens = text.lower().split()
ids = [stoi_map.get(token, unk_idx) for token in tokens]
if len(ids) > max_len:
ids = ids[:max_len]
else:
ids += [pad_idx] * (max_len - len(ids))
return ids
def predict_sentiment_simple(text, model, stoi_map, max_seq_len, pad_idx, unk_idx, device):
model.eval()
with torch.no_grad():
numericalized_ids = numericalize_simple(text, stoi_map, max_seq_len, pad_idx, unk_idx)
text_tensor = torch.tensor(numericalized_ids, dtype=torch.long).unsqueeze(0).to(device)
# 计算实际长度
actual_length = max_seq_len - numericalized_ids.count(pad_idx)
length_tensor = torch.tensor([actual_length], dtype=torch.long) # 不需要移到device,forward会处理
logits = model(text_tensor, length_tensor)
probabilities = F.softmax(logits, dim=1)
predicted_class_id = torch.argmax(probabilities, dim=1).item()
return predicted_class_id, probabilities.squeeze().tolist()
# 示例预测
class_map = {0: "正面", 1: "负面", 2: "中性"} # 与 OUTPUT_DIM 对应
test_sentence_1 = "word1 word5 word100 is great" # 假设这些词在 mock_stoi 中
test_sentence_2 = "bad word200 unknownword"
test_sentence_3 = "word50 so so"
pred_id_1, probs_1 = predict_sentiment_simple(test_sentence_1, model_lstm, mock_stoi, MAX_SEQ_LEN, PAD_IDX, 1, device)
print(f"\n'{test_sentence_1}' -> Predicted: {class_map.get(pred_id_1, '未知')}, Probs: {probs_1}")
pred_id_2, probs_2 = predict_sentiment_simple(test_sentence_2, model_lstm, mock_stoi, MAX_SEQ_LEN, PAD_IDX, 1, device)
print(f"'{test_sentence_2}' -> Predicted: {class_map.get(pred_id_2, '未知')}, Probs: {probs_2}")
pred_id_3, probs_3 = predict_sentiment_simple(test_sentence_3, model_lstm, mock_stoi, MAX_SEQ_LEN, PAD_IDX, 1, device)
print(f"'{test_sentence_3}' -> Predicted: {class_map.get(pred_id_3, '未知')}, Probs: {probs_3}")
代码解释和关键点:
- 参数定义:定义了词汇表大小、序列长度、模型超参数、训练超参数等。
Vocabulary类:build_vocabulary: 统计词频,并根据freq_threshold和max_size构建词表。tokenize: 简单的基于空格的分词和转小写。实际项目中可能会使用更复杂的分词器(如 spaCy, NLTK, Jieba)。numericalize: 将文本转换为 ID 序列,并进行截断或填充到max_len。
preprocess_data函数: 调用Vocabulary的numericalize方法将原始文本数据转换为 (ID序列张量, 标签张量) 的元组列表。TextDataset类: 继承自torch.utils.data.Dataset,实现了__len__和__getitem__。collate_batch函数:- 这是传递给
DataLoader的collate_fn。它的作用是将一批从Dataset获取的样本(每个样本是一个 (text_tensor, label_tensor) 元组)组织成模型训练所需的批次格式。 - 它将文本张量和标签张量分别堆叠起来。
- 关键:它还计算了每个文本序列在填充前的实际长度
length_list。这个长度信息对于nn.utils.rnn.pack_padded_sequence非常重要,可以告诉 RNN/LSTM 不要处理填充部分。
- 这是传递给
DataLoader: 使用TextDataset和collate_batch创建训练和验证数据加载器。TextClassifierLSTM模型: 与之前的定义基本一致,注意forward方法中pack_padded_sequence的使用,以及text_lengths需要在 CPU 上且为long类型。- 训练准备: 实例化模型、损失函数 (
CrossEntropyLoss) 和优化器 (Adam)。 - 训练循环:
model_lstm.train()和model_lstm.eval()用于切换模式。- 从
train_loader获取批次数据(texts_batch, labels_batch, lengths_batch)。 - 梯度清零、前向传播、损失计算、反向传播、梯度裁剪、优化器更新参数。
- 计算并打印训练和验证的损失及准确率。
- 预测函数
predict_sentiment:- 演示了如何使用训练好的模型对新文本进行预测。
- 注意输入文本也需要经过同样的分词、数值化、填充等预处理步骤。
unsqueeze(0)用于将单个样本变成batch_size=1的批次。- 计算长度也需要与训练时
collate_fn的逻辑保持一致。
这个完整的例子展示了从数据准备到模型训练和简单预测的整个流程。在实际应用中,每个步骤可能都会更加复杂和精细,例如使用更高级的分词器、预训练词嵌入、更复杂的数据增强、学习率调度、早停等。