循环神经网络RNN
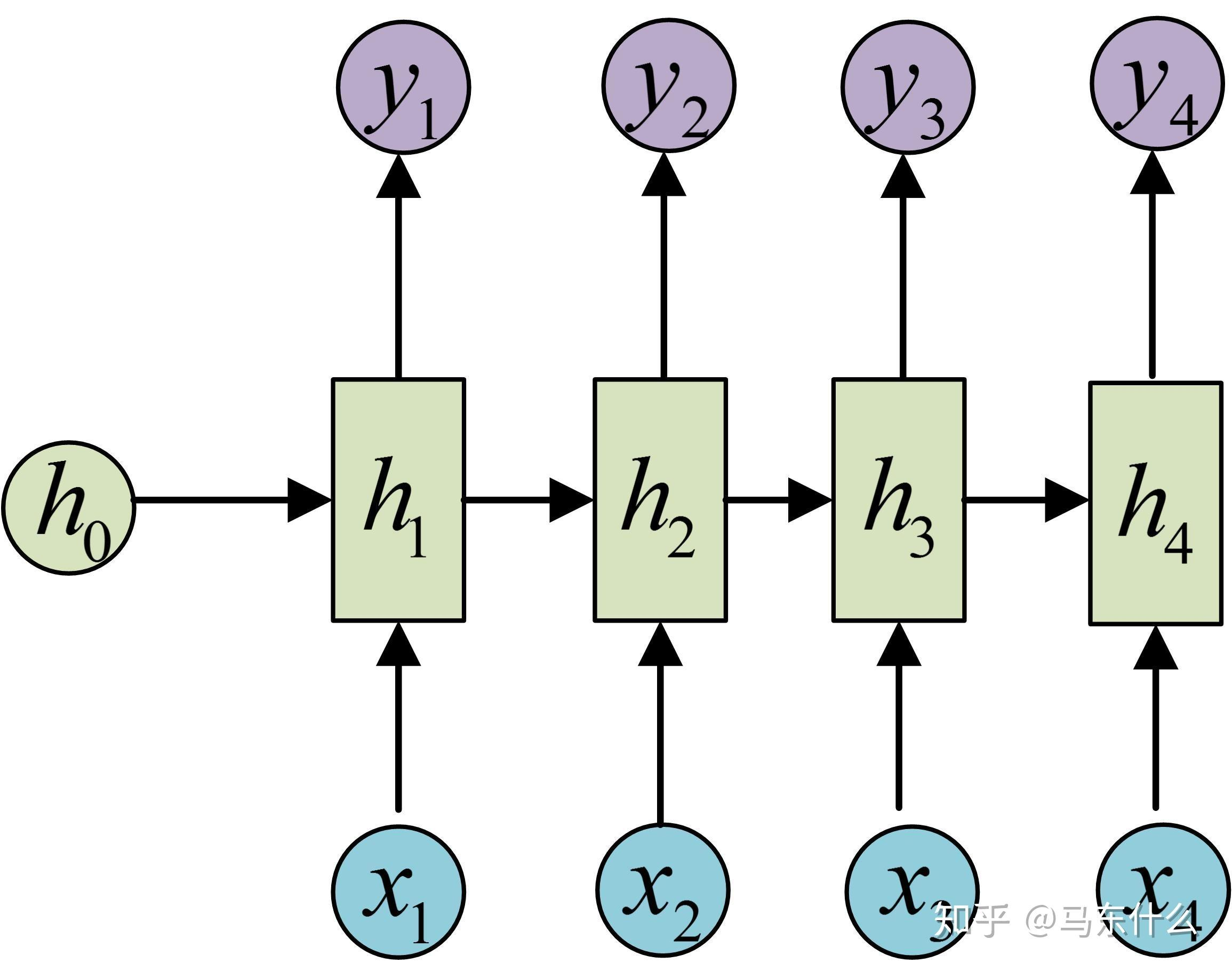
循环神经网络 (RNN) - 使用 GRU 进行序列到序列任务(简化版机器翻译或摘要)
任务假设: 我们有一个源语言句子序列和一个对应的目标语言句子序列(例如,英语到法语的翻译,或者长文本到短摘要)。 模型输入一个源语言句子的词ID序列,输出一个目标语言句子的词ID序列。 这是一个序列到序列 (Seq2Seq) 的模型框架,通常包含一个编码器 (Encoder) 和一个解码器 (Decoder)。
模型结构设想 (Encoder-Decoder 架构):
- 编码器 (Encoder):
Embedding层: 将源语言词ID转换为词嵌入。GRU层 (Gated Recurrent Unit,一种比LSTM更简洁的RNN变体): 读取源语言词嵌入序列,并将其压缩成一个固定大小的上下文向量 (Context Vector),这个向量理论上编码了整个输入序列的信息。
- 解码器 (Decoder):
Embedding层: 将目标语言词ID转换为词嵌入(通常有自己的嵌入层)。GRU层: 以编码器的上下文向量作为初始隐藏状态,并接收上一个时间步预测的目标词和当前的隐藏状态,来生成下一个目标词的预测。Linear层: 将 GRU 的输出映射到目标语言词汇表大小的维度,得到每个目标词的 logits。- (通常还会加入注意力机制 (Attention Mechanism) 来让解码器在生成每个目标词时,可以关注源序列的不同部分,但这里为了简化,我们先不加注意力)。
代码实现 (简化版,不带 Attention,且解码是贪婪的或教师强制的简单形式):
import torch
import torch.nn as nn
import torch.nn.functional as F
import random # 用于教师强制
class EncoderRNN(nn.Module):
def __init__(self, input_vocab_size, embedding_dim, hidden_dim, n_layers, dropout_prob, pad_idx):
super().__init__()
self.embedding = nn.Embedding(input_vocab_size, embedding_dim, padding_idx=pad_idx)
self.gru = nn.GRU(embedding_dim, hidden_dim, n_layers,
dropout=dropout_prob if n_layers > 1 else 0,
batch_first=True, bidirectional=False) # 通常编码器可以是双向的,这里简化为单向
self.dropout = nn.Dropout(dropout_prob)
def forward(self, src_ids, src_lengths):
# src_ids: (batch_size, src_seq_len)
# src_lengths: (batch_size)
embedded = self.dropout(self.embedding(src_ids)) # (batch_size, src_seq_len, embedding_dim)
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, src_lengths.cpu(),
batch_first=True, enforce_sorted=False)
# outputs: (batch_size, src_seq_len, hidden_dim * num_directions) - 如果解包
# hidden: (n_layers * num_directions, batch_size, hidden_dim)
packed_outputs, hidden = self.gru(packed_embedded)
# hidden 是编码器最后的隐藏状态,作为上下文向量
return hidden
class DecoderRNN(nn.Module):
def __init__(self, output_vocab_size, embedding_dim, hidden_dim, n_layers, dropout_prob, pad_idx):
super().__init__()
self.output_vocab_size = output_vocab_size
self.embedding = nn.Embedding(output_vocab_size, embedding_dim, padding_idx=pad_idx)
self.gru = nn.GRU(embedding_dim, hidden_dim, n_layers, # 解码器输入维度是嵌入维度
dropout=dropout_prob if n_layers > 1 else 0,
batch_first=True, bidirectional=False) # 解码器通常是单向的
self.fc_out = nn.Linear(hidden_dim, output_vocab_size)
self.dropout = nn.Dropout(dropout_prob)
def forward(self, decoder_input_id, hidden_context):
# decoder_input_id: (batch_size, 1) - 当前时间步的输入词ID (初始是<SOS>, 之后是上一步预测的词)
# hidden_context: (n_layers, batch_size, hidden_dim) - 来自编码器的上下文或解码器上一步的隐藏状态
# decoder_input_id 需要 unsqueeze(1) 如果不是 (batch_size, 1) 而是 (batch_size)
# 这里假设输入已经是 (batch_size, 1)
embedded = self.dropout(self.embedding(decoder_input_id)) # (batch_size, 1, embedding_dim)
# output: (batch_size, 1, hidden_dim)
# hidden: (n_layers, batch_size, hidden_dim)
output, hidden = self.gru(embedded, hidden_context)
# output 是 (batch_size, seq_len=1, hidden_dim)
# 我们需要 (batch_size, hidden_dim) 送入全连接层
prediction_logits = self.fc_out(output.squeeze(1)) # (batch_size, output_vocab_size)
return prediction_logits, hidden
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src_ids, src_lengths, trg_ids=None, teacher_forcing_ratio=0.5):
# src_ids: (batch_size, src_seq_len)
# src_lengths: (batch_size)
# trg_ids: (batch_size, trg_seq_len) - 训练时提供,推理时为 None
# teacher_forcing_ratio: 训练时使用真实目标词作为下一步输入的概率
batch_size = src_ids.shape[0]
trg_len = trg_ids.shape[1] if trg_ids is not None else MAX_TRG_LEN_INFERENCE # 推理时需要预设最大长度
trg_vocab_size = self.decoder.output_vocab_size
# 存储解码器输出的张量
outputs_logits = torch.zeros(batch_size, trg_len, trg_vocab_size).to(self.device)
# 1. 编码器处理源序列
encoder_hidden_context = self.encoder(src_ids, src_lengths)
# encoder_hidden_context 形状 (n_layers, batch_size, hidden_dim)
# 解码器的第一个输入是 <SOS> (Start Of Sentence) token
# 假设 <SOS> 的 ID 是 1 (需要根据你的词汇表确定)
decoder_input_id = torch.ones((batch_size, 1), dtype=torch.long, device=self.device) * SOS_TOKEN_IDX
# 解码器的初始隐藏状态是编码器的最终隐藏状态
decoder_hidden = encoder_hidden_context
# 2. 解码器逐个生成目标序列的词
for t in range(trg_len): # 遍历目标序列的每个时间步
# decoder_output_logits: (batch_size, trg_vocab_size)
# decoder_hidden: (n_layers, batch_size, hidden_dim)
decoder_output_logits, decoder_hidden = self.decoder(decoder_input_id, decoder_hidden)
outputs_logits[:, t, :] = decoder_output_logits
# 决定下一个解码器的输入:教师强制或使用当前预测
teacher_force = random.random() < teacher_forcing_ratio
top1_predicted_id = decoder_output_logits.argmax(1) # (batch_size)
if self.training and teacher_force and trg_ids is not None:
decoder_input_id = trg_ids[:, t].unsqueeze(1) # 使用真实目标词 (batch_size, 1)
else:
decoder_input_id = top1_predicted_id.unsqueeze(1) # 使用模型自己的预测 (batch_size, 1)
# 如果所有批次都预测了 <EOS> token,可以提前停止 (简化版未实现)
return outputs_logits # (batch_size, trg_seq_len, trg_vocab_size)
# --- 模拟参数 ---
INPUT_VOCAB_SIZE_RNN = 5000
OUTPUT_VOCAB_SIZE_RNN = 5500
EMBEDDING_DIM_RNN = 128
HIDDEN_DIM_RNN = 256
N_LAYERS_RNN = 2
DROPOUT_PROB_RNN = 0.3
PAD_IDX_RNN = 0
SOS_TOKEN_IDX = 1 # 假设 <SOS> 符号的ID
EOS_TOKEN_IDX = 2 # 假设 <EOS> 符号的ID
MAX_TRG_LEN_INFERENCE = 15 # 推理时解码的最大长度
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 实例化编码器和解码器
encoder_rnn = EncoderRNN(INPUT_VOCAB_SIZE_RNN, EMBEDDING_DIM_RNN, HIDDEN_DIM_RNN,
N_LAYERS_RNN, DROPOUT_PROB_RNN, PAD_IDX_RNN).to(device)
decoder_rnn = DecoderRNN(OUTPUT_VOCAB_SIZE_RNN, EMBEDDING_DIM_RNN, HIDDEN_DIM_RNN,
N_LAYERS_RNN, DROPOUT_PROB_RNN, PAD_IDX_RNN).to(device)
# 实例化 Seq2Seq 模型
seq2seq_model = Seq2Seq(encoder_rnn, decoder_rnn, device).to(device)
print("\nSeq2Seq 模型结构 (Encoder):\n", seq2seq_model.encoder)
print("\nSeq2Seq 模型结构 (Decoder):\n", seq2seq_model.decoder)
total_params_seq2seq = sum(p.numel() for p in seq2seq_model.parameters() if p.requires_grad)
print(f"\nSeq2Seq 模型总可训练参数数量: {total_params_seq2seq:,}")
# --- 模拟输入数据 ---
BATCH_SIZE_RNN = 3
SRC_SEQ_LEN_RNN = 10
TRG_SEQ_LEN_RNN = 12 # 训练时的目标序列长度
dummy_src_ids = torch.randint(3, INPUT_VOCAB_SIZE_RNN, (BATCH_SIZE_RNN, SRC_SEQ_LEN_RNN), device=device)
dummy_src_lengths = torch.tensor([10, 8, 9], device=device) # 假设的源序列长度
# 模拟填充
dummy_src_ids[1, 8:] = PAD_IDX_RNN
dummy_src_ids[2, 9:] = PAD_IDX_RNN
dummy_trg_ids = torch.randint(3, OUTPUT_VOCAB_SIZE_RNN, (BATCH_SIZE_RNN, TRG_SEQ_LEN_RNN), device=device) # 训练时的目标
print(f"\n模拟输入源ID形状: {dummy_src_ids.shape}")
print(f"模拟输入目标ID形状 (训练时): {dummy_trg_ids.shape}")
# --- 模型前向传播 (训练模式) ---
seq2seq_model.train() # 设置为训练模式以使用教师强制
output_seq_logits = seq2seq_model(dummy_src_ids, dummy_src_lengths, dummy_trg_ids, teacher_forcing_ratio=0.5)
print("\nSeq2Seq 模型输出 Logits (形状: batch_size, trg_seq_len, output_vocab_size):")
print(output_seq_logits.shape)
# --- 模型前向传播 (推理模式,不提供trg_ids) ---
seq2seq_model.eval()
with torch.no_grad():
# 推理时,trg_ids 为 None,teacher_forcing_ratio 通常为 0
# 注意:这里的 MAX_TRG_LEN_INFERENCE 会在 forward 中被用来确定循环次数
inference_logits = seq2seq_model(dummy_src_ids, dummy_src_lengths, trg_ids=None, teacher_forcing_ratio=0.0)
print("\nSeq2Seq 模型推理输出 Logits 形状:")
print(inference_logits.shape)
Seq2Seq (RNN) 通俗解释:
这个模型像一个“翻译员二人组”:一个“阅读理解员”(编码器)和一个“写作员”(解码器)。
-
EncoderRNN(__init__和forward) (阅读理解员):embedding: 和之前文本分类的嵌入层一样,把源语言的词ID变成“含义向量”。gru: GRU 是一个更现代的循环神经网络单元,比基础 RNN 更能记住长期信息,比 LSTM 参数少一点。它会按顺序“阅读”源语言句子的词向量。forward过程:- 编码器接收源语言句子(词ID和实际长度)。
- 词ID通过嵌入层变成词向量。
pack_padded_sequence同样用于处理填充。- GRU 单元处理这些词向量。最重要的是,当 GRU 读完整个句子后,它会输出一个最终的“隐藏状态” (
hidden)。这个hidden状态就像是编码器对整个源句子的“理解总结”或“思想精华”,我们称之为上下文向量 (context vector)。 - 编码器的任务就是把可变长度的输入句子,浓缩成一个固定大小的上下文向量。
-
DecoderRNN(__init__和forward) (写作员):embedding: 这是解码器自己的嵌入层,用于目标语言的词(例如法语词)。gru: 解码器的 GRU。它也按顺序工作,但它的任务是根据上下文向量和已经生成的目标词,来预测下一个目标词。fc_out: 一个线性层,将解码器 GRU 的输出(表示当前预测词的隐藏信息)转换成目标语言词汇表中每个词的分数(logits)。forward过程 (一次只预测一个词):- 解码器接收两个主要输入:
decoder_input_id: 当前应该输入的词。在开始生成时,这是一个特殊的“句子开始”符号 (<SOS>)。之后,它可以是上一步真实的目标词(训练时的教师强制),或者是上一步模型自己预测的词。hidden_context: 解码器的当前“记忆状态”。第一次调用时,这个状态是编码器给的“上下文向量”。之后,它是解码器自己上一步的隐藏状态。
- 输入词ID通过嵌入层变向量。
- GRU 单元结合嵌入向量和当前的
hidden_context,更新自己的记忆,并输出一个新的“思考结果” (output) 和新的记忆状态 (hidden)。 fc_out层把 GRU 的“思考结果”转换成对目标词汇表中所有词的预测分数 (prediction_logits)。- 它返回预测分数和更新后的记忆状态
hidden(这个hidden会作为下一次预测的hidden_context)。
- 解码器接收两个主要输入:
-
Seq2Seq(__init__和forward) (翻译总指挥):__init__: 把编码器和解码器组合起来。forward过程:- 编码: 首先,把源语言句子 (
src_ids,src_lengths) 交给编码器,得到“上下文向量” (encoder_hidden_context)。 - 准备解码:
- 创建一个空的列表或张量
outputs_logits来存放每一步的预测分数。 - 解码器的第一个输入词是
<SOS>符号。 - 解码器的初始“记忆”就是编码器给的“上下文向量”。
- 创建一个空的列表或张量
- 循环解码:
- 一步一步地生成目标序列中的词,直到达到最大长度或者预测出“句子结束”符号 (
<EOS>)。 - 在每一步
t:- 调用解码器的
forward方法,传入当前的输入词和当前的解码器记忆,得到下一个词的预测分数和更新后的解码器记忆。 - 保存这些预测分数。
- 决定下一步解码器的输入:
- 教师强制 (Teacher Forcing): 在训练时,有一定概率(
teacher_forcing_ratio),我们会直接把真实的目标词作为下一步的输入,而不是用模型自己上一步的预测。这有助于模型更快地学习正确的序列。 - 自由运行: 如果不使用教师强制,或者在推理(测试)时,我们会选择当前预测分数最高的那个词作为下一步的输入。
- 教师强制 (Teacher Forcing): 在训练时,有一定概率(
- 调用解码器的
- 一步一步地生成目标序列中的词,直到达到最大长度或者预测出“句子结束”符号 (
- 最终返回整个目标序列每个位置上所有词的预测分数。
- 编码: 首先,把源语言句子 (
Seq2Seq 如何学习?
损失函数会比较模型生成的整个目标词序列的 logits (outputs_logits) 和真实的目标词序列 (trg_ids)。常用的损失函数是 CrossEntropyLoss,但需要对 logits 和 target 进行适当的变形,因为损失是按每个词计算然后平均或求和的。梯度会从解码器的最后一步一直反向传播到解码器的第一步,然后再传播到编码器,更新所有相关的权重。