循环神经网络RNN
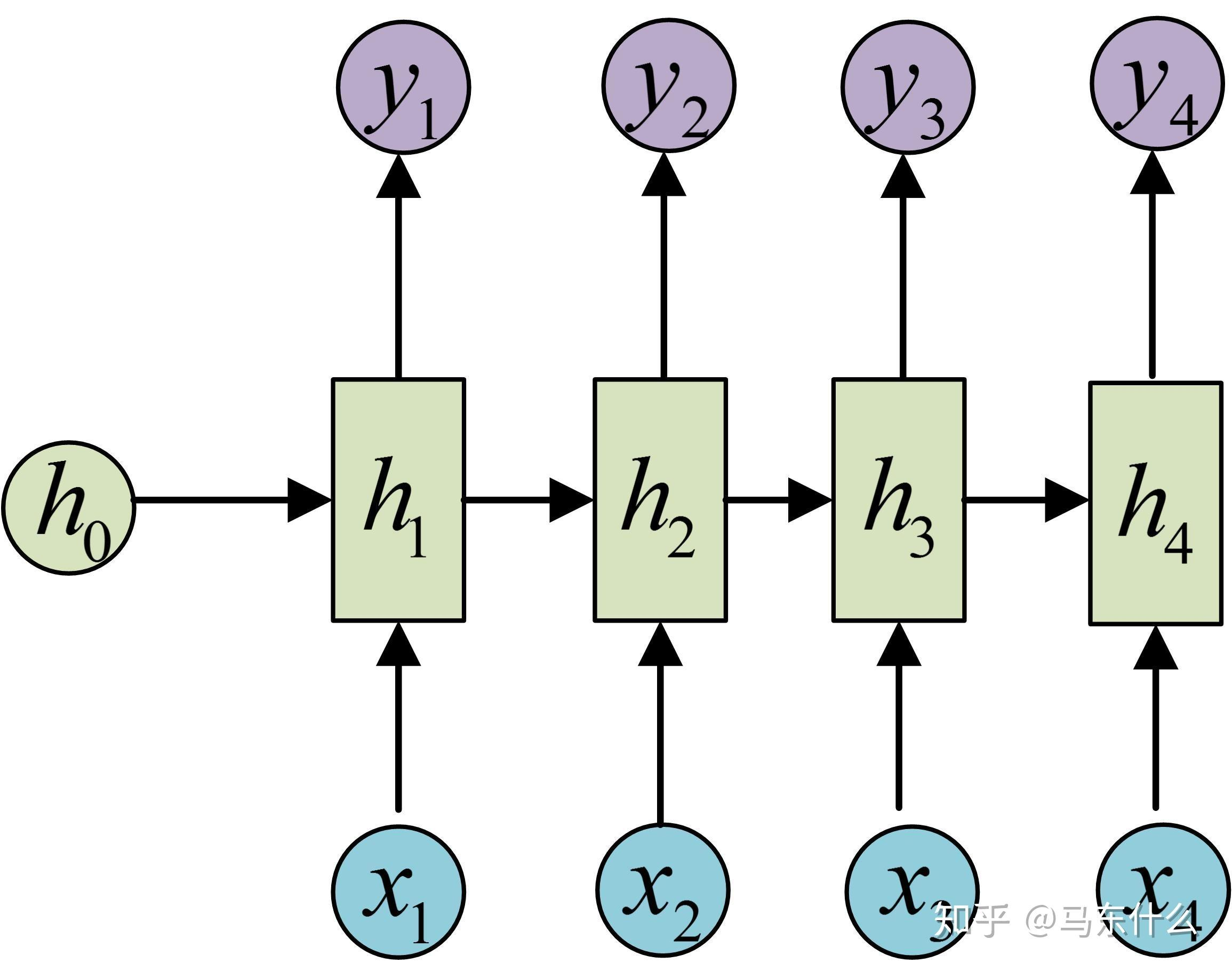
RNN基本原理
想象一下你在读一句话,或者听别人说话。
- 你的大脑是怎么工作的?
- 当你读到或听到一个词时,你不仅仅是理解这个词本身的意思,你还会结合前面已经读过或听过的词来理解当前这个词在整个句子中的含义。
- 比如,听到“我今天感觉很...”,你大脑里会根据前面的“我今天感觉很”来预测后面可能出现的词,比如“开心”、“难过”、“累”等等。
- 你的大脑里似乎有一个**“短期记忆”**,它保存了你刚刚处理过的信息,并用这些信息来帮助理解接下来的内容。
RNN 就是想模拟这种“带有记忆”的处理方式。
普通神经网络 (前馈神经网络) 的局限:
- 想象一个普通的图像识别神经网络,它看到一张猫的图片,然后输出“猫”。它看到一张狗的图片,输出“狗”。
- 它处理每个输入都是独立的,它不会记住之前看过的图片是什么。它没有“上下文”的概念。
- 这种网络不适合处理像句子这样的序列数据,因为句子中词语的顺序和上下文非常重要。
RNN 的核心特点:“循环”与“记忆”
RNN 的神奇之处在于它有一个**“循环” (Recurrent)** 的结构,这个结构让它能够拥有类似“短期记忆”的能力。
-
处理序列中的每个元素:
- RNN 会一个接一个地处理序列中的元素(比如句子中的每个词,或者时间序列中的每个数据点)。
-
“隐藏状态” (Hidden State) —— 扮演短期记忆的角色:
- 在处理每个元素时,RNN 不仅仅看当前的输入,它还会参考一个叫做**“隐藏状态” (Hidden State)** 的东西。
- 这个“隐藏状态”可以看作是 RNN 到目前为止处理过的所有前面元素的**“摘要”或“记忆”**。
-
循环更新记忆:
- 当 RNN 处理完当前这个词(比如“感觉”)后,它会:
- 根据当前的词 (“感觉”) 和 上一时刻的“短期记忆” (比如对“我今天”的记忆) 来更新它的“短期记忆”,形成一个新的“短期记忆” (比如对“我今天感觉”的记忆)。
- 同时,它可能还会根据当前的词和更新后的“短期记忆”来做一个输出 (比如预测下一个词可能是什么,或者对当前词进行某种分类)。
- 这个新的“短期记忆” 会被传递到处理序列中下一个元素(比如“很”)的时候使用。
- 当 RNN 处理完当前这个词(比如“感觉”)后,它会:
-
参数共享:
- 重要的是,RNN 在处理序列中不同位置的元素时,使用的是同一套“规则”或“参数”(权重)。这意味着它学习到的处理方式是通用的,可以应用于序列的不同部分。就像你用同一种语法规则去理解句子的不同部分一样。
简单概括 RNN 的工作流程:
想象 RNN 是一个小机器人,它在读一个单词列表: "我", "爱", "你"
-
读第一个词 "我":
- 机器人看到 "我"。
- 因为它刚开始,没有之前的“记忆”,所以它根据 "我" 更新了自己的“记忆”(比如,记住了句子的主语是“我”)。
- 它可能还会输出一些东西(取决于具体任务)。
-
读第二个词 "爱":
- 机器人看到 "爱"。
- 它会结合当前的词 "爱" 和它对 "我" 的“记忆”,来更新它的“记忆”(比如,现在记住了“我爱...”)。
- 它可能又输出一些东西。
-
读第三个词 "你":
- 机器人看到 "你"。
- 它会结合当前的词 "你" 和它对 "我爱" 的“记忆”,再次更新它的“记忆”(比如,现在记住了整个句子“我爱你”)。
- 它可能又输出一些东西。
这个过程中,“记忆”(隐藏状态)不断地被新的输入所更新,并影响着对后续输入的处理和模型的输出。这就是“循环”的含义——信息在网络内部循环流动,并不断更新状态。
RNN 的优点:
- 能够处理变长的序列数据。
- 能够捕捉到序列中的短期依赖关系(即当前元素与它前面不远处的元素之间的关系)。
- 参数共享使得模型更紧凑,能处理不同长度的序列。
RNN 的挑战 (也是为什么后来发展出 LSTM, GRU 等):
- 短期记忆的瓶颈: 就像普通人一样,基本的 RNN 的“短期记忆”能力有限。当序列非常长的时候,它很难记住很久以前的信息,这被称为长期依赖问题 (Long-Term Dependencies Problem)。
- 梯度消失/爆炸: 在训练很长的序列时,梯度在反向传播过程中可能会变得非常小(梯度消失)或非常大(梯度爆炸),导致模型难以学习。
总结一下:
RNN 的核心原理就是通过一个循环的结构和一个不断更新的隐藏状态(记忆),使得网络在处理序列数据时能够考虑到前面已经出现过的信息。它就像一个有短期记忆的处理器,一步一步地读取序列,并不断更新自己对序列的理解。虽然它有局限性,但它为处理序列数据奠定了重要的基础。
循环神经网络 (RNN) - 使用 GRU 进行序列到序列任务(简化版机器翻译或摘要)
任务假设: 我们有一个源语言句子序列和一个对应的目标语言句子序列(例如,英语到法语的翻译,或者长文本到短摘要)。 模型输入一个源语言句子的词ID序列,输出一个目标语言句子的词ID序列。 这是一个序列到序列 (Seq2Seq) 的模型框架,通常包含一个编码器 (Encoder) 和一个解码器 (Decoder)。
模型结构设想 (Encoder-Decoder 架构):
- 编码器 (Encoder):
Embedding层: 将源语言词ID转换为词嵌入。GRU层 (Gated Recurrent Unit,一种比LSTM更简洁的RNN变体): 读取源语言词嵌入序列,并将其压缩成一个固定大小的上下文向量 (Context Vector),这个向量理论上编码了整个输入序列的信息。
- 解码器 (Decoder):
Embedding层: 将目标语言词ID转换为词嵌入(通常有自己的嵌入层)。GRU层: 以编码器的上下文向量作为初始隐藏状态,并接收上一个时间步预测的目标词和当前的隐藏状态,来生成下一个目标词的预测。Linear层: 将 GRU 的输出映射到目标语言词汇表大小的维度,得到每个目标词的 logits。- (通常还会加入注意力机制 (Attention Mechanism) 来让解码器在生成每个目标词时,可以关注源序列的不同部分,但这里为了简化,我们先不加注意力)。
代码实现 (简化版,不带 Attention,且解码是贪婪的或教师强制的简单形式):
import torch
import torch.nn as nn
import torch.nn.functional as F
import random # 用于教师强制
class EncoderRNN(nn.Module):
def __init__(self, input_vocab_size, embedding_dim, hidden_dim, n_layers, dropout_prob, pad_idx):
super().__init__()
self.embedding = nn.Embedding(input_vocab_size, embedding_dim, padding_idx=pad_idx)
self.gru = nn.GRU(embedding_dim, hidden_dim, n_layers,
dropout=dropout_prob if n_layers > 1 else 0,
batch_first=True, bidirectional=False) # 通常编码器可以是双向的,这里简化为单向
self.dropout = nn.Dropout(dropout_prob)
def forward(self, src_ids, src_lengths):
# src_ids: (batch_size, src_seq_len)
# src_lengths: (batch_size)
embedded = self.dropout(self.embedding(src_ids)) # (batch_size, src_seq_len, embedding_dim)
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, src_lengths.cpu(),
batch_first=True, enforce_sorted=False)
# outputs: (batch_size, src_seq_len, hidden_dim * num_directions) - 如果解包
# hidden: (n_layers * num_directions, batch_size, hidden_dim)
packed_outputs, hidden = self.gru(packed_embedded)
# hidden 是编码器最后的隐藏状态,作为上下文向量
return hidden
class DecoderRNN(nn.Module):
def __init__(self, output_vocab_size, embedding_dim, hidden_dim, n_layers, dropout_prob, pad_idx):
super().__init__()
self.output_vocab_size = output_vocab_size
self.embedding = nn.Embedding(output_vocab_size, embedding_dim, padding_idx=pad_idx)
self.gru = nn.GRU(embedding_dim, hidden_dim, n_layers, # 解码器输入维度是嵌入维度
dropout=dropout_prob if n_layers > 1 else 0,
batch_first=True, bidirectional=False) # 解码器通常是单向的
self.fc_out = nn.Linear(hidden_dim, output_vocab_size)
self.dropout = nn.Dropout(dropout_prob)
def forward(self, decoder_input_id, hidden_context):
# decoder_input_id: (batch_size, 1) - 当前时间步的输入词ID (初始是<SOS>, 之后是上一步预测的词)
# hidden_context: (n_layers, batch_size, hidden_dim) - 来自编码器的上下文或解码器上一步的隐藏状态
# decoder_input_id 需要 unsqueeze(1) 如果不是 (batch_size, 1) 而是 (batch_size)
# 这里假设输入已经是 (batch_size, 1)
embedded = self.dropout(self.embedding(decoder_input_id)) # (batch_size, 1, embedding_dim)
# output: (batch_size, 1, hidden_dim)
# hidden: (n_layers, batch_size, hidden_dim)
output, hidden = self.gru(embedded, hidden_context)
# output 是 (batch_size, seq_len=1, hidden_dim)
# 我们需要 (batch_size, hidden_dim) 送入全连接层
prediction_logits = self.fc_out(output.squeeze(1)) # (batch_size, output_vocab_size)
return prediction_logits, hidden
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src_ids, src_lengths, trg_ids=None, teacher_forcing_ratio=0.5):
# src_ids: (batch_size, src_seq_len)
# src_lengths: (batch_size)
# trg_ids: (batch_size, trg_seq_len) - 训练时提供,推理时为 None
# teacher_forcing_ratio: 训练时使用真实目标词作为下一步输入的概率
batch_size = src_ids.shape[0]
trg_len = trg_ids.shape[1] if trg_ids is not None else MAX_TRG_LEN_INFERENCE # 推理时需要预设最大长度
trg_vocab_size = self.decoder.output_vocab_size
# 存储解码器输出的张量
outputs_logits = torch.zeros(batch_size, trg_len, trg_vocab_size).to(self.device)
# 1. 编码器处理源序列
encoder_hidden_context = self.encoder(src_ids, src_lengths)
# encoder_hidden_context 形状 (n_layers, batch_size, hidden_dim)
# 解码器的第一个输入是 <SOS> (Start Of Sentence) token
# 假设 <SOS> 的 ID 是 1 (需要根据你的词汇表确定)
decoder_input_id = torch.ones((batch_size, 1), dtype=torch.long, device=self.device) * SOS_TOKEN_IDX
# 解码器的初始隐藏状态是编码器的最终隐藏状态
decoder_hidden = encoder_hidden_context
# 2. 解码器逐个生成目标序列的词
for t in range(trg_len): # 遍历目标序列的每个时间步
# decoder_output_logits: (batch_size, trg_vocab_size)
# decoder_hidden: (n_layers, batch_size, hidden_dim)
decoder_output_logits, decoder_hidden = self.decoder(decoder_input_id, decoder_hidden)
outputs_logits[:, t, :] = decoder_output_logits
# 决定下一个解码器的输入:教师强制或使用当前预测
teacher_force = random.random() < teacher_forcing_ratio
top1_predicted_id = decoder_output_logits.argmax(1) # (batch_size)
if self.training and teacher_force and trg_ids is not None:
decoder_input_id = trg_ids[:, t].unsqueeze(1) # 使用真实目标词 (batch_size, 1)
else:
decoder_input_id = top1_predicted_id.unsqueeze(1) # 使用模型自己的预测 (batch_size, 1)
# 如果所有批次都预测了 <EOS> token,可以提前停止 (简化版未实现)
return outputs_logits # (batch_size, trg_seq_len, trg_vocab_size)
# --- 模拟参数 ---
INPUT_VOCAB_SIZE_RNN = 5000
OUTPUT_VOCAB_SIZE_RNN = 5500
EMBEDDING_DIM_RNN = 128
HIDDEN_DIM_RNN = 256
N_LAYERS_RNN = 2
DROPOUT_PROB_RNN = 0.3
PAD_IDX_RNN = 0
SOS_TOKEN_IDX = 1 # 假设 <SOS> 符号的ID
EOS_TOKEN_IDX = 2 # 假设 <EOS> 符号的ID
MAX_TRG_LEN_INFERENCE = 15 # 推理时解码的最大长度
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 实例化编码器和解码器
encoder_rnn = EncoderRNN(INPUT_VOCAB_SIZE_RNN, EMBEDDING_DIM_RNN, HIDDEN_DIM_RNN,
N_LAYERS_RNN, DROPOUT_PROB_RNN, PAD_IDX_RNN).to(device)
decoder_rnn = DecoderRNN(OUTPUT_VOCAB_SIZE_RNN, EMBEDDING_DIM_RNN, HIDDEN_DIM_RNN,
N_LAYERS_RNN, DROPOUT_PROB_RNN, PAD_IDX_RNN).to(device)
# 实例化 Seq2Seq 模型
seq2seq_model = Seq2Seq(encoder_rnn, decoder_rnn, device).to(device)
print("\nSeq2Seq 模型结构 (Encoder):\n", seq2seq_model.encoder)
print("\nSeq2Seq 模型结构 (Decoder):\n", seq2seq_model.decoder)
total_params_seq2seq = sum(p.numel() for p in seq2seq_model.parameters() if p.requires_grad)
print(f"\nSeq2Seq 模型总可训练参数数量: {total_params_seq2seq:,}")
# --- 模拟输入数据 ---
BATCH_SIZE_RNN = 3
SRC_SEQ_LEN_RNN = 10
TRG_SEQ_LEN_RNN = 12 # 训练时的目标序列长度
dummy_src_ids = torch.randint(3, INPUT_VOCAB_SIZE_RNN, (BATCH_SIZE_RNN, SRC_SEQ_LEN_RNN), device=device)
dummy_src_lengths = torch.tensor([10, 8, 9], device=device) # 假设的源序列长度
# 模拟填充
dummy_src_ids[1, 8:] = PAD_IDX_RNN
dummy_src_ids[2, 9:] = PAD_IDX_RNN
dummy_trg_ids = torch.randint(3, OUTPUT_VOCAB_SIZE_RNN, (BATCH_SIZE_RNN, TRG_SEQ_LEN_RNN), device=device) # 训练时的目标
print(f"\n模拟输入源ID形状: {dummy_src_ids.shape}")
print(f"模拟输入目标ID形状 (训练时): {dummy_trg_ids.shape}")
# --- 模型前向传播 (训练模式) ---
seq2seq_model.train() # 设置为训练模式以使用教师强制
output_seq_logits = seq2seq_model(dummy_src_ids, dummy_src_lengths, dummy_trg_ids, teacher_forcing_ratio=0.5)
print("\nSeq2Seq 模型输出 Logits (形状: batch_size, trg_seq_len, output_vocab_size):")
print(output_seq_logits.shape)
# --- 模型前向传播 (推理模式,不提供trg_ids) ---
seq2seq_model.eval()
with torch.no_grad():
# 推理时,trg_ids 为 None,teacher_forcing_ratio 通常为 0
# 注意:这里的 MAX_TRG_LEN_INFERENCE 会在 forward 中被用来确定循环次数
inference_logits = seq2seq_model(dummy_src_ids, dummy_src_lengths, trg_ids=None, teacher_forcing_ratio=0.0)
print("\nSeq2Seq 模型推理输出 Logits 形状:")
print(inference_logits.shape)
Seq2Seq (RNN) 通俗解释:
这个模型像一个“翻译员二人组”:一个“阅读理解员”(编码器)和一个“写作员”(解码器)。
-
EncoderRNN(__init__和forward) (阅读理解员):embedding: 和之前文本分类的嵌入层一样,把源语言的词ID变成“含义向量”。gru: GRU 是一个更现代的循环神经网络单元,比基础 RNN 更能记住长期信息,比 LSTM 参数少一点。它会按顺序“阅读”源语言句子的词向量。forward过程:- 编码器接收源语言句子(词ID和实际长度)。
- 词ID通过嵌入层变成词向量。
pack_padded_sequence同样用于处理填充。- GRU 单元处理这些词向量。最重要的是,当 GRU 读完整个句子后,它会输出一个最终的“隐藏状态” (
hidden)。这个hidden状态就像是编码器对整个源句子的“理解总结”或“思想精华”,我们称之为上下文向量 (context vector)。 - 编码器的任务就是把可变长度的输入句子,浓缩成一个固定大小的上下文向量。
-
DecoderRNN(__init__和forward) (写作员):embedding: 这是解码器自己的嵌入层,用于目标语言的词(例如法语词)。gru: 解码器的 GRU。它也按顺序工作,但它的任务是根据上下文向量和已经生成的目标词,来预测下一个目标词。fc_out: 一个线性层,将解码器 GRU 的输出(表示当前预测词的隐藏信息)转换成目标语言词汇表中每个词的分数(logits)。forward过程 (一次只预测一个词):- 解码器接收两个主要输入:
decoder_input_id: 当前应该输入的词。在开始生成时,这是一个特殊的“句子开始”符号 (<SOS>)。之后,它可以是上一步真实的目标词(训练时的教师强制),或者是上一步模型自己预测的词。hidden_context: 解码器的当前“记忆状态”。第一次调用时,这个状态是编码器给的“上下文向量”。之后,它是解码器自己上一步的隐藏状态。
- 输入词ID通过嵌入层变向量。
- GRU 单元结合嵌入向量和当前的
hidden_context,更新自己的记忆,并输出一个新的“思考结果” (output) 和新的记忆状态 (hidden)。 fc_out层把 GRU 的“思考结果”转换成对目标词汇表中所有词的预测分数 (prediction_logits)。- 它返回预测分数和更新后的记忆状态
hidden(这个hidden会作为下一次预测的hidden_context)。
- 解码器接收两个主要输入:
-
Seq2Seq(__init__和forward) (翻译总指挥):__init__: 把编码器和解码器组合起来。forward过程:- 编码: 首先,把源语言句子 (
src_ids,src_lengths) 交给编码器,得到“上下文向量” (encoder_hidden_context)。 - 准备解码:
- 创建一个空的列表或张量
outputs_logits来存放每一步的预测分数。 - 解码器的第一个输入词是
<SOS>符号。 - 解码器的初始“记忆”就是编码器给的“上下文向量”。
- 创建一个空的列表或张量
- 循环解码:
- 一步一步地生成目标序列中的词,直到达到最大长度或者预测出“句子结束”符号 (
<EOS>)。 - 在每一步
t:- 调用解码器的
forward方法,传入当前的输入词和当前的解码器记忆,得到下一个词的预测分数和更新后的解码器记忆。 - 保存这些预测分数。
- 决定下一步解码器的输入:
- 教师强制 (Teacher Forcing): 在训练时,有一定概率(
teacher_forcing_ratio),我们会直接把真实的目标词作为下一步的输入,而不是用模型自己上一步的预测。这有助于模型更快地学习正确的序列。 - 自由运行: 如果不使用教师强制,或者在推理(测试)时,我们会选择当前预测分数最高的那个词作为下一步的输入。
- 教师强制 (Teacher Forcing): 在训练时,有一定概率(
- 调用解码器的
- 一步一步地生成目标序列中的词,直到达到最大长度或者预测出“句子结束”符号 (
- 最终返回整个目标序列每个位置上所有词的预测分数。
- 编码: 首先,把源语言句子 (
Seq2Seq 如何学习?
损失函数会比较模型生成的整个目标词序列的 logits (outputs_logits) 和真实的目标词序列 (trg_ids)。常用的损失函数是 CrossEntropyLoss,但需要对 logits 和 target 进行适当的变形,因为损失是按每个词计算然后平均或求和的。梯度会从解码器的最后一步一直反向传播到解码器的第一步,然后再传播到编码器,更新所有相关的权重。